
Tổng Hợp Các Dataset Text-to-SQL Chất Lượng Cao Dành Cho Nghiên Cứu AI
0
Tổng Hợp Các Bộ Dữ Liệu Text-to-SQL Tiên Tiến Nhất Đến Năm 2025
Mở Đầu
Trong lĩnh vực nghiên cứu Trí tuệ Nhân tạo (AI) với SQL, chất lượng bộ dữ liệu đóng vai trò cực kỳ quan trọng để nâng cao hiệu năng các ứng dụng Text-to-SQL.
Khi phát triển các mô hình chuyển đổi ngôn ngữ tự nhiên thành câu truy vấn SQL, việc sở hữu bộ dữ liệu đào tạo và đánh giá đa dạng, chất lượng chính là nền tảng để cải thiện khả năng hiểu và sinh câu lệnh chính xác. Bài viết này tổng hợp và giới thiệu các bộ dữ liệu Text-to-SQL tiêu biểu từ 2017 đến năm 2025, giúp các nhà phát triển và nhà nghiên cứu nhanh chóng tiếp cận và khai thác nguồn tài nguyên phong phú. Ngoài ra, chúng ta còn điểm qua những bộ dữ liệu mới nhất năm 2025 và các thông tin liên quan về leaderboard, giấy tờ nghiên cứu để tiện theo dõi.
Giới Thiệu Các Bộ Dữ Liệu Text-to-SQL Nổi Bật
Bộ Dữ Liệu Mới Nhất Năm 2025
TINYSQL
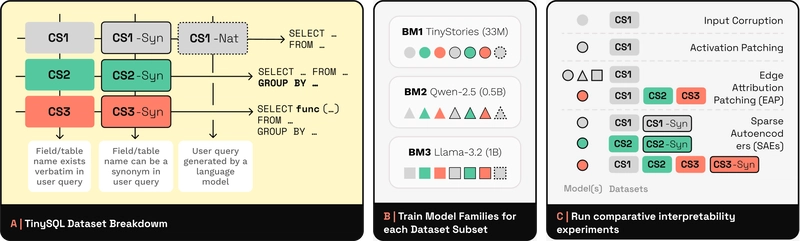
- Mục đích: TINYSQL được thiết kế để hỗ trợ nghiên cứu về tính giải thích (interpretability) của các mô hình Text-to-SQL.
- Đặc điểm: Tập trung vào kiểm soát độ phức tạp của câu truy vấn, từ cơ bản đến nâng cao, giúp phân tích hành vi của mô hình Transformer.
- Ứng dụng: Nghiên cứu cơ chế, kiểm thử công nghệ giải thích mô hình, cải tiến thiết kế bộ dữ liệu tổng hợp.
- Xem paper | Bộ dữ liệu
NL2SQL-Bugs

- Mục đích: Đánh dấu và phát hiện lỗi ngữ nghĩa trong chuyển đổi câu hỏi NL sang SQL.
- Đặc điểm: Bộ dữ liệu 2,018 trường hợp, phân loại lỗi theo 9 loại lớn và 31 loại nhỏ, do chuyên gia chú thích.
- Hiệu quả: Mô hình hiện tại đạt chính xác phát hiện lỗi trung bình 75.16%, phát hiện cả lỗi chú thích trong các bộ tiêu chuẩn BIRD và Spider.
- Xem paper | Bộ dữ liệu
OmniSQL (SynSQL-2.5M)

- Mục đích: Bộ dữ liệu Text-to-SQL tổng hợp lớn nhất với 2.5 triệu mẫu, đa dạng lệ thuộc nhiều cơ sở dữ liệu.
- Đặc điểm: Tổng cộng 16,583 database, hỗ trợ đa dạng cú pháp SQL.
- Cấp phép: Phát hành theo Apache 2.0, có sẵn mô hình OmniSQL 7B/14B/32B.
- Xem paper | Bộ dữ liệu
Thông tin quan trọng: Các bộ dữ liệu năm 2025 được thiết kế để nâng cao khả năng phân tích lỗi, tính giải thích và mở rộng quy mô dữ liệu, hỗ trợ phát triển mô hình có độ tin cậy cao hơn.
Các Bộ Dữ Liệu Tiêu Biểu Khác
Bộ Dữ Liệu | Năm Phát Hành | Đặc Điểm Chính | Link Paper | Link Dataset |
|---|---|---|---|---|
WikiSQL | 2017 | Dữ liệu từ Wikipedia, domain đơn giản, 80,654 câu hỏi | ||
Spider 1.0 | 2018 | Đa domain, đa bảng, khó nhất trong đánh giá cross-domain | ||
SParC | 2019 | Nhiều lượt hỏi, multi-turn, 12k+ câu hỏi | ||
CSpider | 2019 | Phiên bản tiếng Trung của Spider | ||
CoSQL | 2019 | Đối thoại đa lượt query trên 200 DB phức tạp | ||
KaggleDBQA | 2021 | Đánh giá thực tế các DB trên Kaggle, phức tạp | ||
Spider-Syn | 2021 | Tăng cường độ bền với từ đồng nghĩa | ||
SEDE | 2021 | Các truy vấn từ Stack Exchange Data Explorer | ||
BIRD-SQL | 2023 | 12,751 cặp câu hỏi và SQL, 95 DB lớn, 37 domain chuyên sâu | ||
UNITE | 2023 | Hợp nhất 18 bộ dữ liệu, 120k ví dụ và nhiều pattern SQL | ||
Archer | 2024 | Dataset song ngữ Anh - Trung, tập trung vào suy luận phức tạp | ||
BookSQL | 2024 | 100k Query-SQL, tập trung domain kế toán, công bố bảng xếp hạng | ||
Spider 2.0 | 2024 | Bộ test quy trình phức tạp trong doanh nghiệp, đa hệ quản trị | ||
BEAVER | 2024 | Dữ liệu thực tế từ kho dữ liệu doanh nghiệp | ||
PRACTIQ | 2024 | Dataset hội thoại, xử lý truy vấn mơ hồ và không trả lời được | – | |
TURSpider | 2024 | Dataset Tiếng Thổ Nhĩ Kỳ, tương tự Spider về quy mô và cấu trúc | ||
synthetic_text_to_sql | 2024 | Dataset tổng hợp tổng hợp tạo bởi Gretel Navigator | – |
Các Bộ Dữ Liệu Tiêu Chuẩn Và Các Ứng Dụng Phổ Biến
Spider: Tiêu Chuẩn Đánh Giá Mô Hình Cross-domain
Spider được xem là benchmark chuẩn mực với độ khó rất cao trong các bộ dữ liệu Text-to-SQL nhiều database, đa bảng và câu truy vấn phức tạp. Các phiên bản mở rộng như Spider 2.0 còn tập trung vào tình huống thực tế trong doanh nghiệp, dữ liệu lớn với hơn 1,000 cột và tích hợp hệ thống quản trị hiện đại.
BIRD-SQL & NL2SQL-Bugs: Nâng Cao Khả Năng Phát Hiện Lỗi Ngữ Nghĩa
BIRD-SQL với hàng chục nghìn cặp câu hỏi và SQL đa domain được thiết kế để kiểm thử mô hình trong các ngành nghề chuyên sâu như y tế, blockchain, thể thao...
NL2SQL-Bugs dành riêng cho việc phát hiện lỗi logic và ngữ nghĩa sai sót trong câu truy vấn, một bước tiền đề quan trọng trước khi thực hiện sửa lỗi tự động.
Lưu ý: Việc phát hiện và xử lý lỗi ngữ nghĩa trong Text-to-SQL là thách thức lớn giúp nâng cao độ tin cậy của các hệ thống ứng dụng AI.
Tổng Kết
Đến năm 2025, hệ sinh thái các bộ dữ liệu Text-to-SQL đã trở nên đa dạng và phong phú hơn rất nhiều, từ các bộ dữ liệu thực tế, tập trung vào lĩnh vực chuyên ngành, đến những dataset tổng hợp lớn và nổi bật về chất lượng.
Quá trình phát triển này không chỉ thúc đẩy nghiên cứu về độ chính xác của các bộ mô hình chuyển đổi từ ngôn ngữ tự nhiên sang SQL, mà còn mở rộng sang nghiên cứu khả năng giải thích, phát hiện lỗi và tối ưu hiệu năng trong thực tiễn.
Tham Khảo
- Tác giả và các paper từng bộ dataset đã trích dẫn trong phần nội dung
Bài viết được cập nhật liên tục nhằm giới thiệu những bộ dữ liệu mới và tài nguyên hỗ trợ nghiên cứu Text-to-SQL toàn diện.
Loading...