
Postgres vs. Qdrant: Cuộc đối đầu 50 triệu Embeddings, ai sẽ là bá chủ?
0
So Sánh Timescale: Postgres vs. Qdrant với 50 Triệu Embeddings – Hiệu Suất AI Đỉnh Cao
Mở Đầu
Trong thế giới AI hạ tầng, có một niềm tin rằng bạn phải từ bỏ cơ sở dữ liệu đa năng để đạt được hiệu suất cao khi làm việc với vector. Nhưng liệu điều này có thật sự đúng?
Khi ứng dụng trí tuệ nhân tạo ngày càng phổ biến, việc lựa chọn hệ quản trị cơ sở dữ liệu đáp ứng được nhu cầu lưu trữ và truy vấn vector quy mô lớn trở thành một thử thách không nhỏ. Một quan điểm phổ biến là các hệ quản trị cơ sở dữ liệu chuyên biệt như Qdrant mới thật sự mang lại hiệu suất vượt trội trong việc tìm kiếm vector, trong khi các hệ quản trị đa năng như Postgres thường bị coi là không đủ khả năng.
Tuy nhiên, với benchmark mới từ Timescale Launch Week, chúng tôi trình bày một thực tế mới: Postgres với các extension pgvector và pgvectorscale có thể xử lý hiệu quả tới 50 triệu embeddings, duy trì độ trễ đáp ứng dưới 100ms và đạt được throughput đáng kinh ngạc. Bài viết này sẽ phân tích chi tiết kết quả thử nghiệm, lợi ích thực tiễn của Postgres khi sử dụng cho các ứng dụng AI dựa trên vector, cũng như so sánh với Qdrant.
Bài Toán Thử Nghiệm: Postgres và Qdrant Trên 50 Triệu Embeddings
Môi Trường Thử Nghiệm
Chúng tôi so sánh Postgres (cài đặt với các extension pgvector và pgvectorscale) và Qdrant trên cơ sở sau:
- Dữ liệu gồm 50 triệu embeddings, mỗi embedding có 768 chiều
- Sử dụng ANN-benchmarks, công cụ benchmark công nghiệp tiêu chuẩn dành cho tìm kiếm approximate nearest neighbors (ANN)
- Tập trung hoàn toàn vào tìm kiếm ANN mà không áp dụng bộ lọc
- Các bài kiểm tra được chạy trên phần cứng AWS giống hệt nhau, đảm bảo tính công bằng
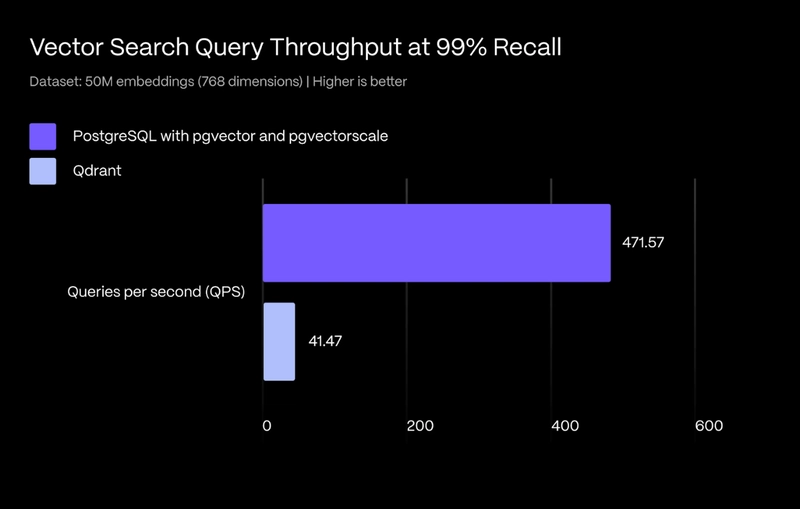
Kết Quả Nổi Bật
Hệ Thống | Throughput (Queries/giây) | Độ trễ p99 (ms) |
|---|---|---|
Postgres + pgvector + pgvectorscale | 471.57 | < 100 |
Qdrant | 41.47 | Tốt ở độ trễ đuôi |
Điểm quan trọng: Postgres vượt trội về throughput đáng kể, trong khi Qdrant có lợi thế về thời gian xây dựng chỉ mục và độ trễ "đuôi" (tail latency).
Tại Sao Kết Quả Này Lại Quan Trọng?
Lợi Ích Khi Dùng Postgres Cho AI Vector Workloads
- Độ trễ cho sản xuất: Postgres đảm bảo độ trễ p99 dưới 100ms, phù hợp cho các ứng dụng AI thời gian thực hoặc tương tác nhanh.
- Tăng khả năng đồng thời: Throughput cao hơn giúp phục vụ nhiều người dùng cùng lúc mà không cần mở rộng cơ sở hạ tầng quá mức.
- Giảm độ phức tạp: Không cần tích hợp hệ thống vector database riêng biệt, giảm thiểu rủi ro vận hành và chi phí.
- Tận dụng nền tảng quen thuộc: Dùng Postgres giúp tận dụng toàn bộ hệ sinh thái, từ công cụ hỗ trợ đến thực tiễn vận hành đã được chứng minh.
- Phát triển SQL-first: Có thể kết hợp lọc dữ liệu, join với các bảng quan hệ một cách tự nhiên, không cần học API hay ngôn ngữ truy vấn mới.
Postgres với pgvector và pgvectorscale đem lại sự cân bằng giữa hiệu suất và trải nghiệm nhà phát triển mà nhiều vector database chuyên biệt không thể có được.
Bí Quyết Thành Công: pgvectorscale và StreamingDiskANN
Cách Thức Hoạt Động
pgvectorscale là một extension trong hệ sinh thái pgai phát triển bởi Timescale, triển khai chỉ số StreamingDiskANN – thuật toán ANN dựa trên đĩa (disk-based), tối ưu cho quy mô lớn.- Kết hợp cùng Statistical Binary Quantization (SBQ) giúp cân bằng giữa dung lượng bộ nhớ và hiệu năng
- Tránh nhược điểm của các giải thuật ANN trong bộ nhớ như HNSW, vốn tiêu thụ nhiều RAM và khó mở rộng
- Giải pháp bao gồm:
- Chỉ số lưu trữ trên đĩa, hạn chế lớn bộ nhớ RAM
- Hiệu năng duy trì ổn định khi tăng quy mô tới hàng trăm triệu vector
- Triển khai trên phần cứng đám mây tiêu chuẩn, không cần GPU hay phần cứng đặc thù
Tóm Tắt
Tính năng | pgvectorscale + StreamingDiskANN | HNSW Truyền Thống |
|---|---|---|
Bộ nhớ RAM cần thiết | Thấp hơn nhờ sử dụng đĩa | Rất cao |
Khả năng mở rộng | Tốt, quy mô hàng trăm triệu vector | Giới hạn do bộ nhớ |
Hiệu suất tìm kiếm | Ổn định dưới 100ms độ trễ p99 | Có thể giảm với quy mô lớn |
Phần cứng | Phần cứng tiêu chuẩn AWS (CPU + đĩa) | Cần máy có RAM lớn/GPU |
Khi Nào Nên Chọn Postgres? Khi Nào Không?
Khi Nên Chọn Postgres
- Teams đã có cơ sở dữ liệu Postgres trong hệ thống
- Cần tốc độ truy vấn cao cùng khả năng mở rộng quy mô lớn
- Yêu cầu tích hợp vector search với dữ liệu quan hệ phức tạp
- Muốn duy trì vận hành đơn giản, giảm số lượng công nghệ khác nhau
- Ưu tiên phát triển dựa trên SQL với API chuẩn, dễ tiếp cận
Khi Nên Xem Xét Qdrant
- Trường hợp chưa dùng Postgres và muốn có hệ thống vector chuyên biệt ngay từ đầu
- Các yêu cầu đặc thù cần tốc độ build chỉ mục cực nhanh hoặc độ trễ đuôi thấp hơn
- Cần tính năng vector database chuyên sâu như scale-out tự nhiên hoặc các phép toán vector chuyên biệt
Qdrant là một lựa chọn mạnh, nhưng không phải lúc nào cũng cần thiết phải "đánh đổi" sang hệ quản trị vector chuyên biệt nếu bạn không thực sự cần.
Bạn Muốn Thử Nghiệm Ngay Chứ?
- Tạo tài khoản Timescale Cloud miễn phí để dùng cả hai công cụ trên cực nhanh
Vector search trên Postgres không phải là một hack hay giải pháp trá hình. Đó là một giải pháp mạnh mẽ, dễ triển khai, có thể mở rộng quy mô, và hoàn toàn đủ sức để phát triển các ứng dụng AI production trong năm 2025 và xa hơn nữa.
Tiếp Theo Tại Timescale Launch Week
Sắp tới chúng tôi sẽ giới thiệu cách truyền dữ liệu từ S3 vào Postgres bằng livesync for S3, cùng cách kết hợp xử lý dữ liệu S3 trực tiếp qua pgai Vectorizer – những công cụ làm giàu dữ liệu AI một cách liền mạch trong hệ sinh thái Postgres.
Tham Khảo
- Timescale Blog. (2025). Postgres vs Qdrant trên 50M Embeddings
- Timescale Blog. (2024). Cách Timescale làm cho Postgres nhanh như Pinecone
- GitHub - pgvector: https://github.com/pgvector/pgvector
- GitHub - pgvectorscale: https://github.com/timescale/pgvectorscale
- ANN-Benchmarks: https://github.com/erikbern/ann-benchmarks
Loading...