
Khám phá Kho Báu Dữ Liệu Text2SQL: Bí Kíp Nâng Tầm AI trong Lập Trình SQL!
0
Tổng Quan Các Bộ Dữ Liệu Text-to-SQL Nổi Bật Từ 2017 Đến 2025
Mở Đầu
Trong lĩnh vực nghiên cứu trí tuệ nhân tạo (AI) đặc biệt là Text-to-SQL, việc cải thiện khả năng áp dụng phụ thuộc rất lớn vào chất lượng bộ dữ liệu. Để phát triển các mô hình dịch từ ngôn ngữ tự nhiên sang câu truy vấn SQL chính xác, việc tổng hợp và xây dựng các bộ dữ liệu huấn luyện và đánh giá chuyên biệt trở thành nhu cầu cấp thiết.
Bài viết này sẽ cung cấp một cái nhìn tổng quan và chi tiết về các bộ dữ liệu Text-to-SQL đã được công bố trong những năm gần đây, phân loại theo thời gian và điểm mạnh của từng bộ dữ liệu. Trong đó, tập trung giới thiệu các bộ dữ liệu mới nhất trong năm 2025, cùng các bộ dữ liệu tiêu biểu đã tạo nền tảng cho lĩnh vực này.
Giới Thiệu Các Bộ Dữ Liệu Text-to-SQL Tiêu Biểu
Bộ Dữ Liệu Đánh Giá Quan Trọng: Spider và BIRD-SQL
Spider là bộ dữ liệu đa miền, đa bảng và được nhiều chuyên gia xem như thách thức lớn trong đánh giá Text-to-SQL. BIRD-SQL theo sau là bộ dữ liệu quy mô lớn, bao phủ 37 miền chuyên ngành khác nhau với hơn 12,751 cặp câu hỏi và truy vấn, dành cho bài toán đa miền và cơ sở dữ liệu phức tạp.
Tổng Quan Các Bộ Dữ Liệu Cũ Đến 2024
- WikiSQL (2017): Dữ liệu đơn miền, tập trung câu truy vấn SQL đơn giản.
- SParC (2019): Hỗ trợ phân tích ngữ cảnh, đa lượt hỏi liên tiếp.
- CoSQL (2019): Bộ thoại tương tác, phức tạp, đa miền.
- CHASE (2021): Bộ dữ liệu tiếng Trung hỗ trợ khảo sát ngữ cảnh đa cơ sở dữ liệu.
- EHRSQL (2023): Ứng dụng trong lĩnh vực hồ sơ sức khỏe điện tử với các câu hỏi thực tế.
- UNITE (2023): Thống nhất 18 bộ dữ liệu, đa dạng về miền và loại truy vấn.
Những Bộ Dữ Liệu Mới Nhất Năm 2025
NL2SQL-Bugs: Nhận Diện Lỗi Ngữ Nghĩa Trong Dịch NL2SQL
NL2SQL-Bugs là bộ dữ liệu tiên phong trong việc phát hiện và phân loại lỗi ngữ nghĩa trong các câu truy vấn SQL sinh ra từ ngôn ngữ tự nhiên.
- Số lượng: 2,018 mẫu có chú thích lỗi chi tiết
- Phân loại lỗi: 9 loại chính, 31 loại phụ
- Độ chính xác phát hiện lỗi của mô hình lớn hiện tại: 75.16%
- Phát hiện được 122 lỗi chú thích trong bộ BIRD và Spider

Đây là bộ dữ liệu quan trọng giúp tăng khả năng phát hiện và sửa lỗi ngữ nghĩa trong các hệ thống NL2SQL.
OmniSQL (SynSQL-2.5M): Bộ Dữ Liệu Tổng Hợp Lớn Nhất Hiện Nay
OmniSQL SynSQL-2.5M là bộ dữ liệu tổng hợp với quy mô cực lớn, đại diện cho dataset tổng hợp đa miền lớn nhất tính đến 2025.
- Số mẫu: 2,5 triệu câu hỏi SQL - ngôn ngữ tự nhiên
- Số lượng cơ sở dữ liệu: 16,583
- Được tạo hoàn toàn bằng kỹ thuật tổng hợp dữ liệu từ các mô hình lớn mã nguồn mở
- Phát hành dưới giấy phép Apache 2.0 cho phép phát triển tự do
- Các mô hình OmniSQL tương ứng được cung cấp với quy mô 7B, 14B, 32B tham chiếu

Bộ dữ liệu này đại diện cho nỗ lực lớn nhất nhằm xây dựng nguồn dữ liệu đa dạng, toàn diện cho học máy Text-to-SQL.
TinySQL: Bộ Dữ Liệu Cho Nghiên Cứu Giải Thích Mô Hình
TinySQL tập trung vào nghiên cứu khả năng giải thích của các mô hình Text-to-SQL thông qua việc kiểm soát độ phức tạp của câu truy vấn và ngôn ngữ tự nhiên.
- Hỗ trợ từ câu truy vấn đơn giản đến phức tạp
- Phục vụ cho phân tích hành vi mô hình và kiểm định công nghệ giải thích
- Góp phần nâng cao chất lượng thiết kế dữ liệu tổng hợp
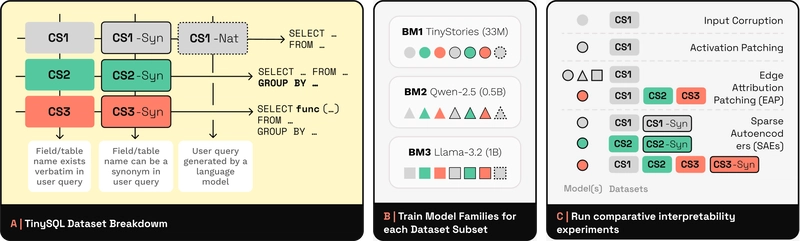
Đây là bộ dữ liệu phù hợp với các nghiên cứu về giải thích mô hình (interpretability) và phân tích hành vi transformer trong Text-to-SQL.
Các Bộ Dữ Liệu Text-to-SQL Nổi Bật Khác
Bộ Dữ Liệu | Năm | Đặc Điểm Chính | Link Đến Bộ Dữ Liệu |
|---|---|---|---|
WikiSQL | 2017 | Dữ liệu đơn miền, đơn giản | |
SParC | 2019 | Hỗ trợ truy vấn theo ngữ cảnh, đa lượt hội thoại | |
CoSQL | 2019 | Dữ liệu hội thoại, phức tạp, đa miền | |
CHASE | 2021 | Tiếng Trung, đa cơ sở dữ liệu, hỗ trợ hội thoại | |
Spider-DK | 2021 | Tăng cường tính bền vững khi xử lý kiến thức miền | |
EHRSQL | 2023 | Ứng dụng trong Hồ sơ sức khỏe điện tử | |
UNITE | 2023 | Gộp 18 bộ dữ liệu với hơn 120k ví dụ, nhiều mẫu SQL | |
Archer | 2024 | Dataset song ngữ Anh - Trung cho bài toán xử lý suy luận phức tạp | |
BookSQL | 2024 | Bộ dữ liệu chuyên ngành kế toán với 100k câu hỏi SQL | |
Spider 2.0 | 2024 | Mục tiêu đánh giá Text-to-SQL trong môi trường doanh nghiệp có quy mô lớn | |
BEAVER | 2024 | Dữ liệu từ thực tế kho dữ liệu doanh nghiệp với lịch sử người dùng | |
PRACTIQ | 2024 | Đối thoại Text-to-SQL với các truy vấn thiếu rõ ràng, không thể trả lời | giấy |
TURSpider | 2024 | Dataset tiếng Thổ Nhĩ Kỳ tương tự Spider | |
synthetic_text_to_sql | 2024 | Bộ dữ liệu tổng hợp chất lượng cao, phát triển bởi Gretel Navigator |
Ứng Dụng và Ý Nghĩa Của Các Bộ Dữ Liệu Text-to-SQL
- Giúp các nhà nghiên cứu và phát triển mô hình có nguồn dữ liệu phong phú để huấn luyện và đánh giá mô hình.
- Thúc đẩy phát triển các kỹ thuật mới nhằm cải thiện độ chính xác dịch ngôn ngữ tự nhiên sang SQL.
- Tăng cường khả năng phát hiện, sửa lỗi và giải thích trong quá trình dịch với bộ dữ liệu như NL2SQL-Bugs.
- Phục vụ nghiên cứu đa ngôn ngữ, đa miền, mở rộng khả năng ứng dụng vào thực tiễn.
Việc có sẵn và đa dạng các bộ dữ liệu Text-to-SQL có ý nghĩa then chốt giúp thúc đẩy sự phát triển của trí tuệ nhân tạo trong lĩnh vực cơ sở dữ liệu, đặc biệt trong tự động hóa truy vấn và khai thác dữ liệu.
Kết Luận
Việc chuẩn bị và công bố đa dạng bộ dữ liệu Text-to-SQL với tính đặc trưng, quy mô và độ phức tạp khác nhau đã tạo ra nền tảng vững chắc cho nghiên cứu và ứng dụng AI trong lĩnh vực SQL. Từ WikiSQL đơn giản năm 2017 đến các bộ dữ liệu lớn, phong phú như OmniSQL, NL2SQL-Bugs đến các bộ dữ liệu chuyên biệt như BookSQL hay TURSpider, cộng đồng nghiên cứu ngày càng có thêm nhiều công cụ để phát triển những mô hình dịch ngôn ngữ mạnh mẽ, chính xác và có khả năng giải thích.
Nếu bạn là nhà phát triển hoặc nhà nghiên cứu AI trong lĩnh vực SQL, hãy thường xuyên theo dõi các bộ dữ liệu mới nhất để tận dụng tối đa sức mạnh của dữ liệu chất lượng cao trong việc huấn luyện và đánh giá mô hình của mình.
Tham Khảo
- Spider 1.0: Paper , Leaderboard
- BIRD-SQL: Paper , Leaderboard May 1, 2023
- Spider 2.0: Paper & Leaderboard August 1, 2024
- Awesome Text2SQL Dataset Repositories:
- SQLFlash Blog về Dataset Text-to-SQL: https://sqlflash.ai/blog/sql-llm-dataset/
Tổng hợp và biên tập bởi chuyên gia AI và xử lý ngôn ngữ tự nhiên.
Loading...