
Bản Thiết Kế Hạ Tầng AI/MLOps Hiện Đại: Chinh Phục Thế Giới AI Với 'Siêu Phẩm' LLM!
0
Kiến Trúc Phát Triển Hạ Tầng AI/MLOps Hiện Đại Cho Ứng Dụng AI Tiên Tiến
Mở Đầu
Sự bùng nổ của các mô hình ngôn ngữ lớn (LLM), hệ thống đa phương thức và RAG (retrieval-augmented generation) đang tạo ra một kỷ nguyên mới cho AI. Điều này cũng đòi hỏi hạ tầng AI/MLOps phải được nâng cấp để đáp ứng các yêu cầu vận hành phức tạp và mở rộng quy mô.
Trong bối cảnh đó, các framework MLOps truyền thống không còn đủ sức xử lý những thách thức lớn như phục vụ các LLM hàng tỷ tham số, quản lý cơ sở dữ liệu vector cho tìm kiếm ngữ nghĩa, hoặc kiểm soát tài nguyên GPU một cách hiệu quả về mặt chi phí. Bài viết này mang đến một bản thiết kế chi tiết về các công cụ và mô hình phát triển nhằm xây dựng hạ tầng AI/MLOps phù hợp với các ứng dụng AI mới nhất.
Chúng ta sẽ cùng khám phá từng thành phần cốt lõi của hạ tầng, từ quản lý vòng đời mô hình LLM, hạ tầng embedding và vector database, đến quản lý tài nguyên GPU, quy trình kỹ thuật prompt và dịch vụ API phục vụ mô hình AI.
1. Quản Lý Vòng Đời Mô Hình LLM
a) Bộ Công Cụ Phổ Biến
- Model Hubs: Hugging Face, Replicate
- Fine-tuning: Axolotl, Unsloth, TRL
- Phục vụ mô hình: vLLM, Text Generation Inference (TGI)
- Orchestration: LangChain, LlamaIndex
b) Những Yếu Tố Quan Trọng
- Quản lý phiên bản cho trọng số adapter như LoRA hay QLoRA để dễ dàng cập nhật và tái sử dụng
- Tích hợp framework thử nghiệm A/B để so sánh các biến thể mô hình khác nhau
- Phân bổ quota GPU hợp lý giữa các nhóm phát triển nhằm tối ưu chi phí và hiệu quả sử dụng

Bảo trì toàn bộ vòng đời mô hình LLM đòi hỏi sự phối hợp chặt chẽ giữa nhiều công cụ hỗ trợ từ việc fine-tuning, phục vụ đến giám sát, giúp đảm bảo tính linh hoạt, hiệu suất và khả năng mở rộng.
2. Cơ Sở Dữ Liệu Vector và Hạ Tầng Embedding
a) Lựa Chọn Cơ Sở Dữ Liệu Vector
Công nghệ | Đặc điểm nổi bật |
|---|---|
Pinecone | Dễ triển khai, hỗ trợ đa dạng |
Weaviate | Tích hợp AI, linh hoạt |
Milvus | Hiệu suất cao, mở rộng tốt |
PGVector | Phục vụ tốt cho PostgreSQL |
QDrant | Mã nguồn mở, tối ưu tìm kiếm |
b) Quy Trình Embedding Hiệu Quả
- Chia tài liệu thành các đoạn nhỏ với phần chồng lắp token ~512-1024 để giữ ngữ cảnh liền mạch
- Xử lý batch embedding bằng thư viện như SentenceTransformers để tăng thông lượng
- Theo dõi hiện tượng embedding drift qua công cụ như Evidently AI để đảm bảo embedding không bị lệch theo thời gian
3. Quản Lý Tài Nguyên GPU
a) Mô Hình Triển Khai
- Dedicated Hosts: thích hợp cho khối lượng công việc ổn định
- NVIDIA DGX: chuyên gia cho deep learning quy mô lớn
- Kubernetes: sử dụng Device Plugins để quản lý GPU hiệu quả
- Serverless: phù hợp với khối lượng bất định, bursty
- Spot Instances: giải pháp chi phí thấp, tăng hiệu quả kinh tế
b) Kỹ Thuật Tối Ưu
- Kỹ thuật lượng tử hóa như GPTQ, AWQ giúp giảm kích thước mô hình và tăng tốc inferencing
- Batching liên tục (continuous batching) với vLLM nâng cao hiệu suất GPU
- FlashAttention hỗ trợ tiết kiệm bộ nhớ trong quá trình xử lý mô hình
Quản lý GPU thông minh là then chốt để đảm bảo hạ tầng vừa đạt được hiệu suất cao, vừa kiểm soát chi phí dịch vụ AI.
4. Quy Trình Kỹ Thuật Prompt (Prompt Engineering Workflows)
a) Tích Hợp MLOps
- Phiên bản hóa prompt song song với mô hình qua các công cụ như Weights & Biases
- Kiểm thử prompt bằng framework đánh giá như Ragas để đảm bảo hiệu quả thực tế
- Triển khai cập nhật prompt với mô hình canary deployment nhằm giảm thiểu rủi ro trong vận hành

Xem prompt như một thành phần sản xuất cần kiểm soát phiên bản và đánh giá, giúp AI hoạt động ổn định và có thể kiểm chứng được chất lượng.
5. Dịch Vụ API Phục Vụ Mô Hình AI
a) Mô Hình Triển Khai
Framework | Đặc điểm | Độ trễ trung bình |
|---|---|---|
FastAPI | Dịch vụ Python đơn giản | < 50ms |
Triton | Đa framework, tối ưu GPU | < 10ms |
BentoML | Đóng gói mô hình trung bình | Phù hợp cho workload scalable |
Ray Serve | Phân tán, quy mô lớn | |
b) Tính Năng Thiết Yếu
- Tự động mở rộng quy mô (autoscaling) dựa trên thanh khoản thực tế
- Hợp nhất các yêu cầu (request batching) để tối ưu xử lý
- Giới hạn lưu lượng truy cập theo token nhằm bảo vệ tài nguyên
Kiến Trúc Hạ Tầng Toàn Diện
Dưới đây là sơ đồ tổng thể mô tả hạ tầng AI Ops bao gồm tất cả thành phần trên phối hợp hoạt động:
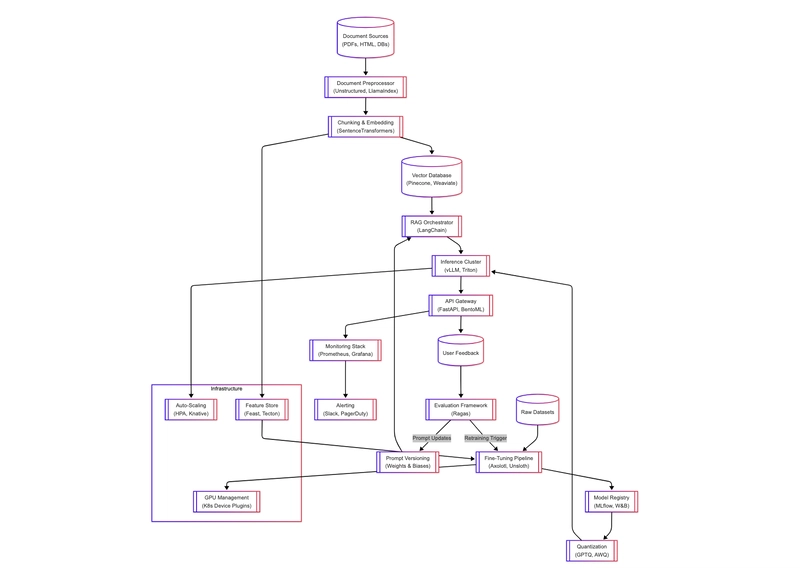
Hạ tầng đầy đủ này giúp giải quyết các thách thức từ việc phục vụ mô hình LLM quy mô lớn cho đến tối ưu chi phí và khả năng quan sát vận hành.
Kết Luận
Việc phát triển một hạ tầng AI/MLOps hiện đại đòi hỏi một tầm nhìn xuyên suốt và phối hợp đồng bộ nhiều công nghệ mới. Những bài học nhanh cần ghi nhớ gồm:
- Phân chia rõ ràng giữa máy tính huấn luyện và máy phục vụ inferencing để tối ưu hiệu quả
- Tự động mở rộng GPU dựa trên tình trạng sử dụng thực tế
- Xem prompt như một thành phẩm cần quản lý trong quy trình phát hành AI
- Giám sát đồng thời chất lượng mô hình và chỉ số hạ tầng để chủ động xử lý
Kiến trúc này sẽ giúp tổ chức triển khai ứng dụng AI có khả năng mở rộng, tiết kiệm chi phí, dễ dàng bảo trì và quan sát tổng thể toàn hệ thống.
Tham Khảo
Cảm ơn bạn đã theo dõi bài viết. Hy vọng hướng dẫn này sẽ giúp bạn tự tin xây dựng và vận hành hạ tầng AI/MLOps hiện đại đối mặt với những thách thức phức tạp hiện nay.
Loading...